

Die Google Indexierung ist die Voraussetzung, damit eine Website Traffic durch Suchmaschinen-Nutzer generiert. Eine feinjustierte Crawling- und Indexierungslogik verschafft viele Vorteile für den Webmaster. In diesem Beitrag erfährst Du, was beachtet werden muss, damit eine Website bzw. ein Online Shop von Google optimal gecrawlt und indexiert werden kann.
Inhaltsverzeichnis
- Du brauchst keine Google Indexierung beauftragen
- Google Indexierung einer Domain/ URL prüfen
- Google um erneutes Crawlen bitten
- Dauer der Google Indexierung einplanen
- Google Indexierung verhinden
- Google Indexierung löschen
- Unterschied zwischen crawlen und indexieren beachten
- Filter- und Sortierungsparameter gezielt indexieren
- Achtung bei AJAX und JavaScript-Inhalten
Du brauchst keine Google Indexierung beauftragen
![]()
Eine Anmeldung zur Indexierung von Inhalten ist bei Google und anderen Suchmaschinen nicht notwendig. Suchmaschinen-Bots besuchen eine Domain selbstständig und indexieren die Ressourcen, welche gecrawlt und indexiert werden dürfen. Die schnellste Möglichkeit eine Domain bei Google bekannt zu machen, ist die Erstellung eines Google Search Console-Profils, ehemals Google Webmaster-Tools.
Google Indexierung einer Domain/ URL prüfen
Google Special Searches bietet Möglichkeiten, verschiedene Spezialabfragen in der Google Suche durchzuführen. Verwende den Suchoperator „info:“, um den Indexierungsstatus einer URL zu ermitteln, zum Beispiel:
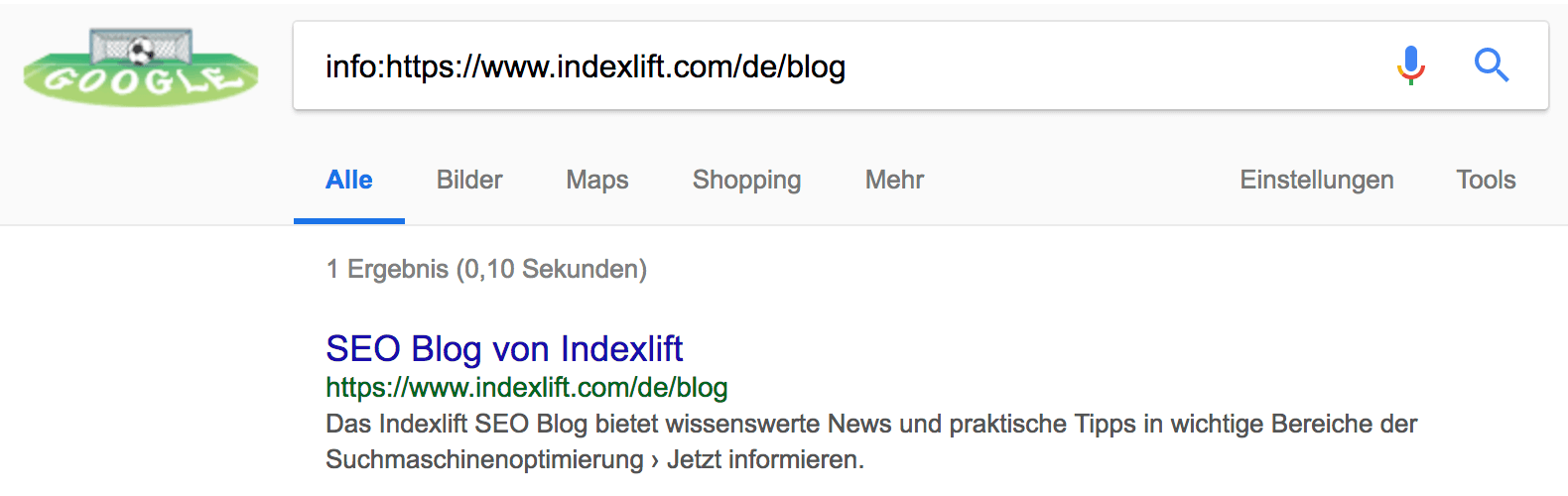
Wenn Du eine Übersicht der indexierten URLs einer Domain oder Verzeichnisses wünschst, hilft der „site:“-Suchoperator weiter. Beachte jedoch, dass die Ergebnisse nicht immer den tagesaktuellen Indexierungsstand darstellen. Der site-Operator verschafft Dir einen groben Überblick.
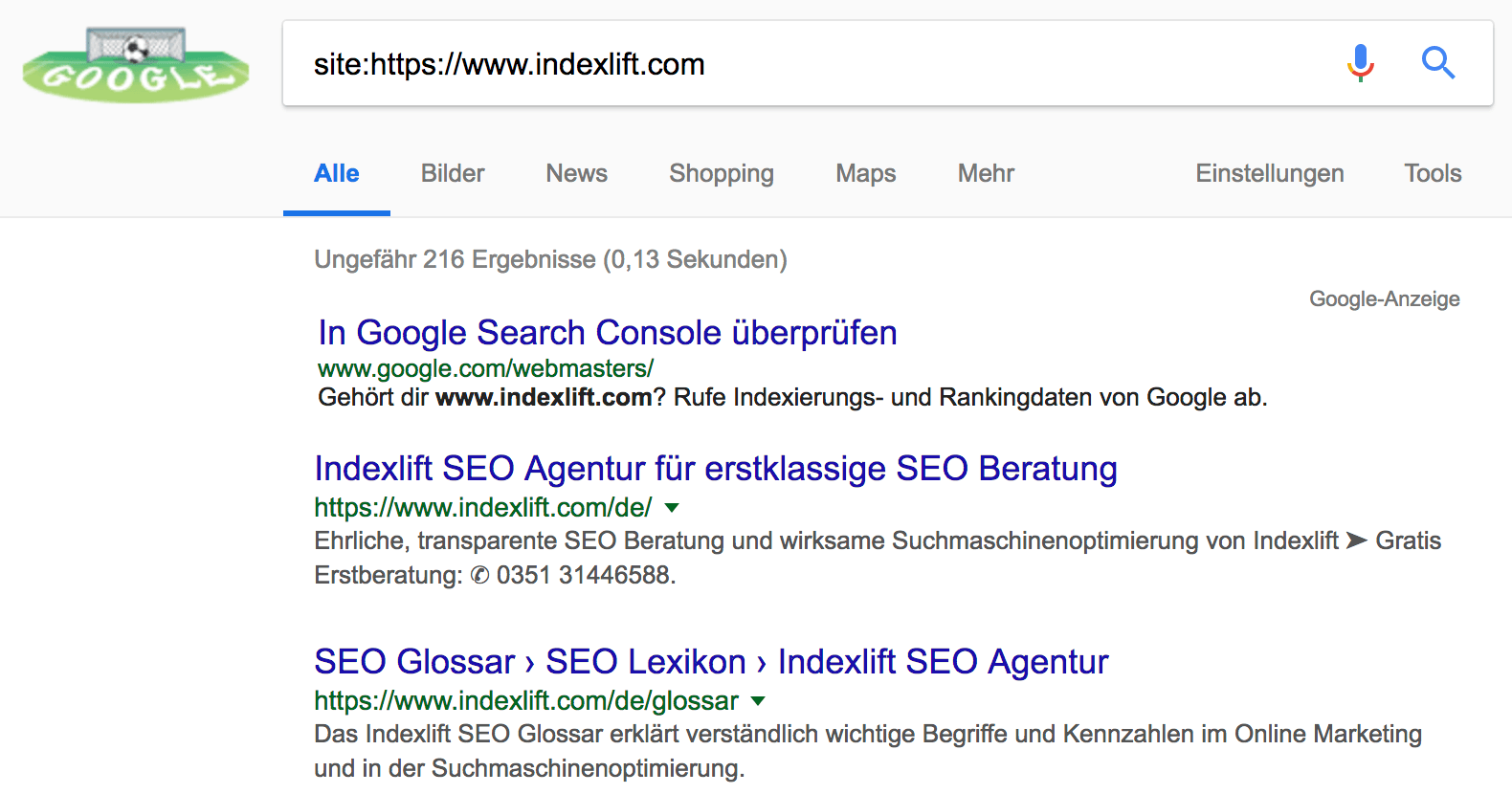
Wenn Dir das nicht ausreicht, empfehle ich einen Datenexport der indexierten URLs aus der Google Search Console. Der Bericht „Indexabdeckung“ in der neuen Search Console-Version bietet Dir verschiedene Filtermöglichkeiten und schließlich den Datenexport an, so dass Du die indexierten Seiten als CSV-Datei herunterladen kannst.
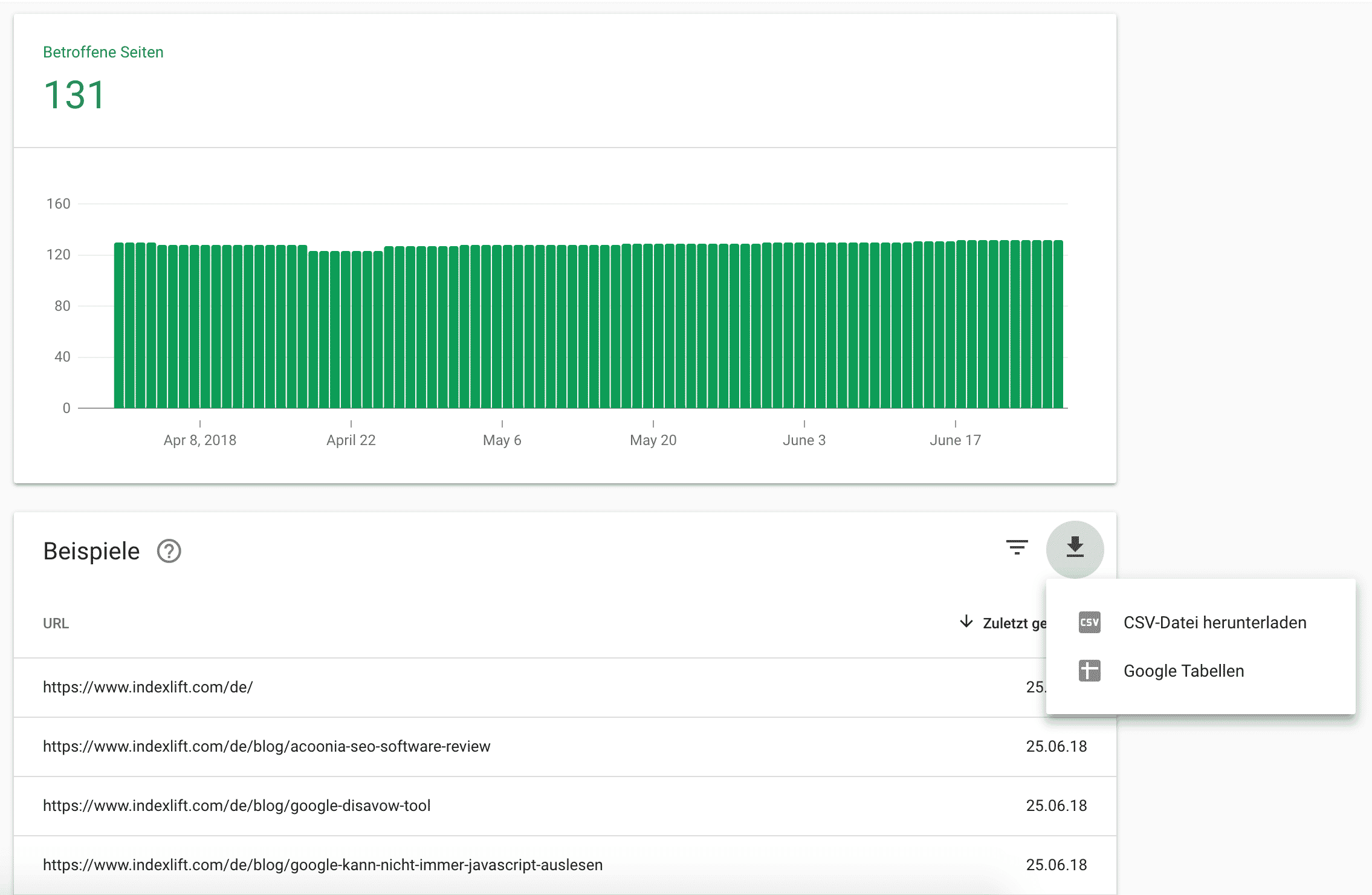
Ab Juli 2018 sollte allen Webmastern auch das Tool zur „URL-Prüfung“ in der neuen Google Search Console zur Verfügung stehen. Damit ist es noch einfacher, den Indexierungsstatus für einzelne URLs zu ermitteln und die Indexierung bei Google einreichen zu können.

Google um erneutes Crawlen bitten
Wenn Du kürzlich Inhalte aktualisiert hast und eine schnelle Aktualisierung des Google Cache einer URL wünschst, empfehle ich das Tool „Abruf wie durch Google“ in der Search Console zu nutzen. Gib die betreffende URL an und wähle nun „Abrufen und Rendern“. Anschließend bewertest Du das gerenderte Ergebnis und wenn alles richtig aussieht, wähle „Indexierung beantragen“.
Dauer der Google Indexierung einplanen
Wie lange es dauert, bis eine neue Website vollständig gecrawlt und indexiert ist, hängt vom Umfang ab. Meist dauert es mehrere Wochen, bis die Google Indexierung abgeschlossen ist. Große Websites und Shops mit mehreren tausend Seiten sollten XML Sitemaps bereitstellen. Diese solltest Du in der Search Console einreichen. In der XML Sitemap empfehle ich nur URLs aufzulisten, die einen HTTP Statuscode 200 liefern, gecrawlt und indexiert werden dürfen und kein Canonical Tag auf eine andere Ressource besitzen. Einzelne HTML Seiten können in der Search Console mit der Funktion „Abruf wie durch Google“ gerendert und die Indexierung beantragt werden.
Solltest Du einen Relaunch oder Redesign planen, empfehle ich Dir meine SEO Checkliste für einen erfolgreichen Website Relaunch. Hier findest Du viele Tipps, damit Deine neue Website schnell indexiert wird und obsolete URLs aus dem Suchindex gelöscht werden können.
Google Indexierung verhinden
Interne Duplikate, Seiten mit wenig Inhalt und diverse Filter- und Sortierungsergebnisse sollten nicht indexiert werden. Entweder Du schließt das Crawlen dieser Ressourcen durch robots.txt-Anweisungen aus und verhinderst die Indexierung mit der Robots Meta Tag-Anweisung „nofollow“ oder Du lässt Suchmaschinen-Bots die Ressourcen crawlen aber verhinderst eine Google Indexierung mit der Robots Meta Tag-Anweisung „nofollow“. Im weiteren Inhalt gehe ich darauf näher ein.
Google Indexierung löschen
Wenn indexierte Seiten aus dem Google Index entfernt werden sollen, empfiehlt sich eine Aktualisierung des Robots Meta Tag durch die Anweisung „noindex“. Wichtig ist, dass keine robots.txt-Anweisung das Crawlen verhindert. Du kannst das in der Google Search Console mit dem robots.txt-Tester analysieren. Beachte auch, dass es Monate dauern kann, bis die URL deindexiert ist. Von der Methode zur Deindexierung mittels Canonical Tag rate ich ab, weil diese nicht erfolgsversprechend ist.
Möchtest Du URLs vorübergehend aus den Google Suchergebnissen entfernen, bietet sich das Tool zum Entfernen von URLs an. Die URLs werden nur vorübergehend entfernt. Eine dauerhafte Löschung bietet das Tool nicht.
Unterschied zwischen crawlen und indexieren beachten
Welche Ressourcen von Suchmaschinen gecrawlt werden dürfen, legen die Anweisungen der robots.txt-Datei fest. Die Textdatei wird im Stammverzeichnis vom Webserver bereitgestellt. Alles Wissenswerte zur robots.txt-Datei erfährst Du in meinem SEO-Tutorial: robots.txt ohne Programmierkenntnisse erstellen und optimieren.
Suchmaschinen-Bots verarbeiten die robots.txt-Datei, bevor sie die Website oder den Shop durchsuchen. Ob eine Ressource (HTML Datei, Bild, PDF-Datei) die gecrawlt werden darf, in den Suchindex aufgenommen wird, hängt von individuellen Einstellungen ab. Für klassische HTML Seiten wird die Indexierung durch Robots Meta Tag-Anweisungen und optional durch ein Canonical Tag festgelegt. Doch die Suchmaschine entscheidet schließlich selbst, ob eine Ressource indexiert wird. Der Webmaster kann das nicht erzwingen. Zusammengefasst:
- robots.txt-Anweisungen definieren, welche Ressourcen von Suchmaschinen-Bots und Web-Scrapern nicht gecrawlt werden dürfen.
- Robots Meta Tag und Canonical Tag weisen an, ob eine crawlbare Ressource indexiert werden darf.
- Optional: In der Google Search Console kann festgelegt werden, wie URL-Parameter vom Googlebot gehandhabt werden sollen.
Filter- und Sortierungsparameter gezielt indexieren
Online Shops bieten ihren Nutzern häufig Filter und Sortierungsmöglichkeiten an. Doch viele Ergebnisse sollten von Suchmaschinen-Bots nicht indexiert zu werden, wenn es dafür keine Suchanfragen in der Google Suche gibt. Das betrifft oft sehr individuelle Suchmuster (siehe Liste) und kombinierte Filter, die sehr spezielle Filterergebnisse liefern. SEOs gehen oft einen Schritt weiter und schließen die Ergebnisse durch robots.txt-Anweisungen vom Crawlen aus, um den internen PageRank effektiver zu verteilen, wie:
- Größenfilter
- Farbfilter
- Preisfilter
- Bewertungsfilter
- Produkte pro Seite
- Sortierung der Ergebnisse (z. B: Von A bis Z)
- Kombinierte Filter mit speziellen Ergebnissen
- …
In jedem Fall ist eine clevere Indexierungslogik für Filter- und Sortierungsparameter ratsam, weil so die Crawlability spürbar verbessert wird. Doch das muss für jeden Shop individuell konfiguriert werden. Das folgende Beispiel zeigt die Filter-Optionen einer Kategorieseite vom aboutyou-Shop:

Achtung bei AJAX und JavaScript-Inhalten
Seit 2016 ist Google in der Lage JavaScript-Inhalte zu rendern und zu crawlen. JavaScript wird vom Browser ausgeführt. Das Rendern der Inhalte muss somit der Googlebot übernehmen, damit die JavaScript-Inhalte gecrawlt und indexiert werden können. Bei AJAX ist das anders. Wichtige Inhalte sollten nicht per AJAX-Request nachgeladen werden, denn das Crawlen von AJAX-Schema hat Google 2018 eingestellt. Das bedeutet: Inhalte, die in den HTML Quellcode nachgeladen werden, können von Suchmaschinen nicht gecrawlt werden. (Weitere Infos)




Es gibt aber auch extra SEO Tools, die sich nur mit dem crawlen befassen. Mit diesen kann man besser auswerten wie gut oder schlecht das crawlen lief und diesen Vorgang ganz gemütlich optimieren. Ich lass einfach mal meine Empfehlung hier.
Das wäre dann das Programm deep crawl, wobei Screaming Frog auch ganz gut ist.
Hoffe das Hilft, danke für den Beitrag und Gruß
Thomas