

Das Canonical Tag ist ein HTML-Tag, um Duplicate Content auf einer Seite zu vermeiden. Durch einen kanonischen Link werden Suchmaschinen informiert, welche Adresse in den Suchergebnissen bevorzugt werden soll.
Inhaltsverzeichnis
- Welche Seite bevorzugt Google?
- Anwendungsfälle zur Kanonisierung
- Canonical Tags sind nicht immer die beste Methode
- Methoden für die Kanonisierung
- Kanonische URL prüfen
- Kombination aus Canonical Tag und noindex
- Canonical Tag und Paginierung
- Canonical Tag mit Selbstverweis
- Duplicate Content Checker
- Best practices für Canonical Tags
Welche Seite bevorzugt Google?
Auf großen Websites kann es passieren, dass mehrere URLs das selbe Thema behandeln oder sich Themen überschneiden. Googlebot bevorzugt die Seite, die am umfangreichsten und nützlichsten zu sein scheint und kennzeichnet sie als kanonisch. Um das Crawlbudget der Website bestmöglich auszuschöpfen, verarbeitet Google kanonische URLs häufiger, als andere. Neben dem Canonical Tag nutzt Google auch weitere Faktoren, um die kanonische URL zu ermitteln:
- Wird die Seite über HTTP oder HTTPS bereitgestellt?
- Wie lautet die bevorzugte Domain des Nutzers?
- Welche Qualität besitzt die Seite?
- Wird die URL in einer Sitemap aufgeführt?
- usw.
Anwendungsfälle zur Kanonisierung
Für folgende Anwendungsfälle bietet es sich an, bevorzugte URLs zu ermitteln und festzulegen, zum Beispiel:
- Zur Unterstützung mehrerer Gerätetypen, wenn das Layout nicht responsiv ist:
- https://mobil.example.com
- https://www.example.come
- Bei URLs mit Suchparameter oder Sitzungs-IDs.
- Bei der Bereitstellung einer HTML-Druckversion.
- Bei exakten Inhalten einer HTML-Seite und PDF-Datei.
- Wenn ein Produkt in einem Shop mehreren Kategorien zugeordnet wird.
Canonical Tags sind nicht immer die beste Methode
Canonical Tags sind häufig eine gute Lösung zur Vermeidung von Duplicate Content. Doch sie sind nicht immer die beste Methode. Drei Beispiele dazu:
Beispiel 1: Mehrfach exakt gleiche Inhalte
URLs mit exakt gleichem Inhalt sollten durch Redirects zur bevorzugten Adresse weiterleiten. Wie Google mitteilt, besitzen Weiterleitungen einen stärkeren Einfluss auf die Kanonisierung, als das rel=“canonical“-Link-Attribut und Sitemaps:

Beispiel 2: HTTP und HTTPS
Sind Seiten auf einer Website durch HTTP und HTTPS erreichbar, ist eine globale Redirect Regel die technisch beste Lösung. Sie kann in der .htaccess-Datei (Apache-Server) hinterlegt werden. Diese Regel leitet von HTTP automatisch auf HTTPS mit einem 301-Statuscode weiter. Hierfür ist ein SSL-Zertifikat (Let’s encrypt) erforderlich.
|
1 2 3 |
RewriteEngine on RewriteCond %{HTTPS} !=on RewriteRule ^ https://%{HTTP_HOST}%{REQUEST_URI} [L,R=301] |
Beispiel 3: Parameter-URLs
Viele Shops verwenden Filter, um Seiteninhalte nach gewünschten Kriterien einzuschränken. Diese Filterergebnisse generieren häufig eine eigenständige URL mit Parameter. Parameter-URLs bieten sich zum indexieren an, wenn für das individuelle Filterergebnis ein geeignetes Suchvolumen vorhanden ist, etwa „braune Damenstiefel“. URLs mit mehreren Parametern sind in der Regel zum indexieren nicht geeignet, weil das Filterergebnis zu spezifisch ist, wie „adidas Sneaker weiß Größe 43“. Google empfiehlt URLs, die auf keinen Fall gecrawlt werden sollen, durch robots.txt-Anweisungen zu blockieren. Besonders in großen Shops wirkt sich das positiv auf die Crawlability aus, weil es wenig Sinn macht tausende Parameter-URLs für Filterergebnisse zu crawlen, die nicht indexiert werden sollen.
Methoden für die Kanonisierung
Methode 1: Canonical Tag im HTML-Code
Die für die meisten einfachste Methode ist die Verwendung vom rel=“canonical“-Link-Attribut Mit href wird die kanonische URL (absolut angeben) festgelegt, die Googlebot bevorzugen soll. rel=“canonical“ wird im <head>-Bereich einer Seite angegeben.
|
1 2 3 4 5 6 7 |
<html> <head> <link rel="canonical" href="https://www.example.com/page" /> (…) </head> <body>Sichtbarer Bereich einer Webseite</body> </html> |
Wer Shopify oder WordPress verwendet, dem empfehle ich das Yoast SEO Plugin mit dem die Indexierbarkeit und die Verwendung von Canonical Tags individuell festgelegt werden kann, ohne im Quellcode Anpassungen vornehmen zu müssen.
Methode 2: Canonical Tag im HTTP-Header
Google unterstützt diese Methode derzeit nur für Websuchergebnisse.
Ist der Server konfigurierbar, kann die kanonische URL mithilfe des HTTP-Headers rel=“canonical“ angegeben werden. Das funktioniert für ein von der Google Suche unterstütztes Dokument, einschließlich Nicht-HTML-Dokumenten, wie PDF-Dateien.
|
1 |
Link: <https://www.example.com/page>; rel="canonical" |
Methode 3: Kanonische URLs in der Sitemap
Alle Seiten, die in einer XML Sitemap notiert sind, werden als kanonisch vorgeschlagen. Google entscheidet dann basierend auf der Ähnlichkeit der Inhalte, welche Seiten als (potenziell) dupliziert gelten.
Durch die Angabe der bevorzugten kanonischen URLs in der Sitemap kann man auf einfache Weise kanonische URLs für eine große Website definieren. Sitemaps sind nützlich, weil sie Google mitteilen, welche Seiten einer Website am wichtigsten sind.
Methode 4: Weiterleitungen
Die Methode eignet sich, um vorhandene duplizierte Seiten zu entfernen.
Alle Weiterleitungsmethoden (301- und 302-Weiterleitungen, meta-refresh sowie JavaScript-Weiterleitungen) haben die gleichen Auswirkungen auf die Google Suche, wobei 3xx-HTTP-Weiterleitungen die schnellste Wirkung erzielen.
Methode 5: Anweisung in der .htaccess
Alternativ zu den ersten beiden Methoden kann eine kanonische URL auch mittels .htaccess-Eintrag erfolgen. Diese Methode bietet sich auch für PDF-Dateien an.
Zur Konfiguration einer kanonischen URL in der .htaccess-Datei wird das Apache Modul mod_headers verwendet. Hierfür wird eine Anweisung nach dem folgenden Schema in der .htaccess-Datei hinzugefügt:
|
1 2 3 4 5 |
<IfModule mod_expires.c> <Files canonical-tag.pdf> Header append Link "<https://www.example.com/page>; rel=\"canonical\"" </Files> </IfModule> |
Die Seite (https://www.example.com/page) soll gegenüber der PDF-Datei (canonical-tag.pdf) bevorzugt werden.
Nachteil Der Nachteil dieser Methode ist das Aufblähen der .htaccess-Datei. Je größer diese Datei wird, desto schlechter können die Ladezeiten ausfallen.
Warum erzeugen PDF-Dateien Duplicate Content?
Duplicate Content liegt auch vor, wenn eine HTML Seite und eine maschinenlesbare PDF Datei exakte oder sehr ähnliche Inhalte besitzen. Manchmal brechen Keyword-Rankings in den Suchmaschinen Ergebnissen ein oder schwanken stark.
Das folgende Beispiel zeigt eine Keyword-Kannibalisierung von einer HTML Seite (rot) und einer PDF Datei (blau) mit exakt gleichen Inhalten für das selbe Keyword einer Website. Das ist aus SEO-Sicht ungünstig und sollte durch Kanonisierung behoben werden.
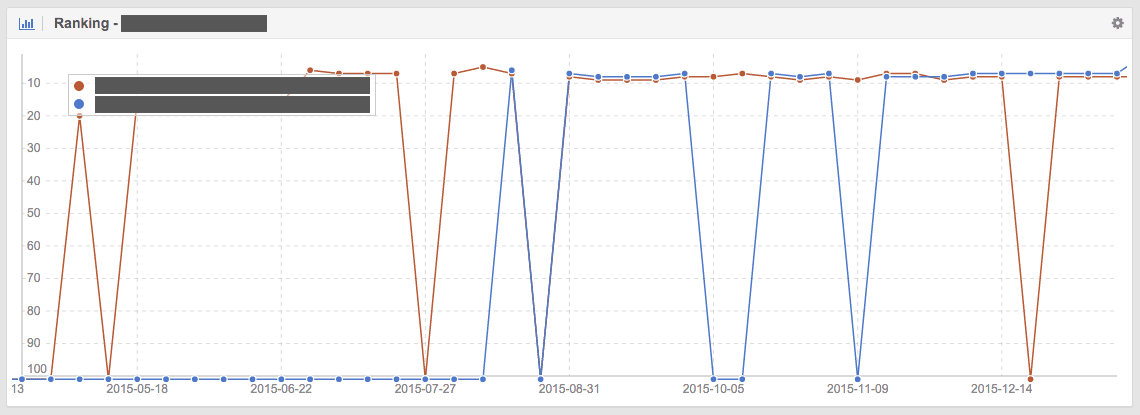
Kanonische URL prüfen
Mit dem Bericht URL-Prüfung (Indexabdeckung) der Google Search Console kann für eine URL ermittelt werden, ob Google eine kanonische URL erkannt hat und welche URL Google als kanonisch bestimmt hat.
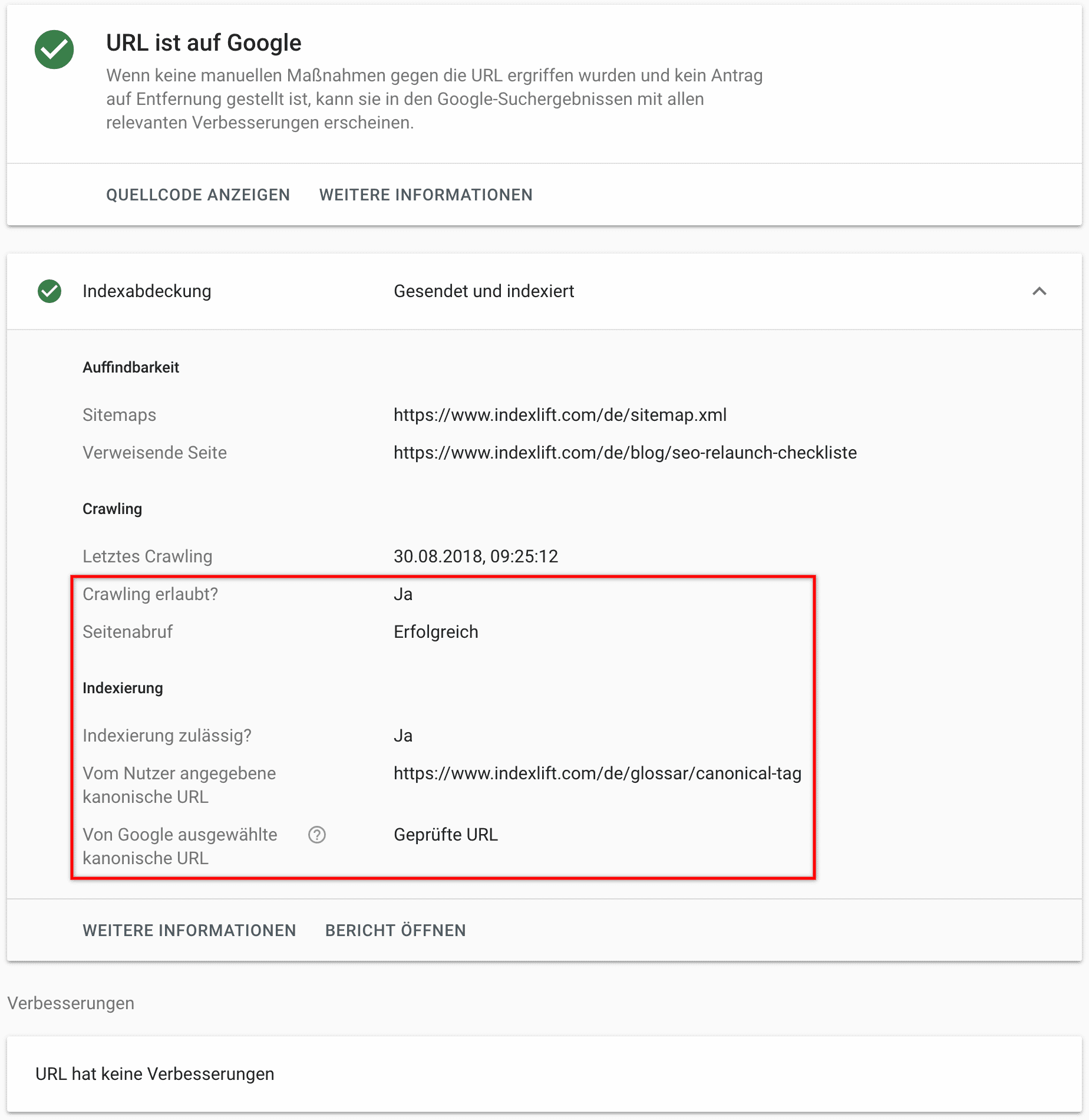
Alternativ bietet sich das kostenfreie Online-Tool Canonical Tag URL Location Checker zur schnellen Validierung an. Ich verwende die Chrome Erweiterung Detailed SEO Extension, die Informationen zur Indexierung und kanonischen URL liefert.
Kombination aus Canonical Tag und noindex
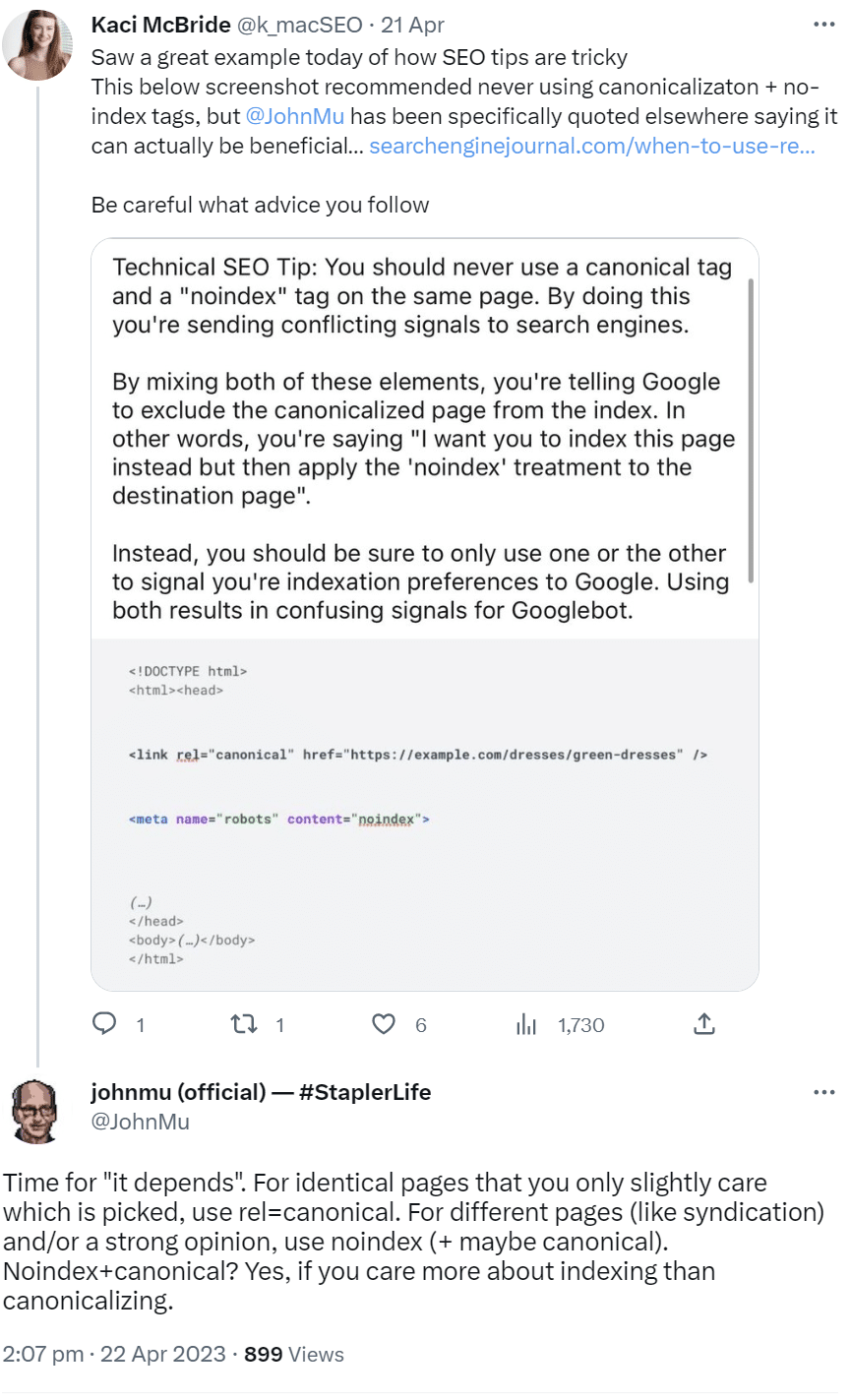
Laut John Müller von Google kann es in bestimmten Fällen sinnvoll sein, einen Canonical-Link und noindex auf derselben Seite zu kombinieren. Zum Beispiel bei unterschiedlichen Seiten mit syndizierten Inhalten. Darüber hinaus kann es auch bei einer eindeutigen Bewertung sinnvoll sein, ein noindex zu verwenden und gegebenenfalls mit einem Canonical-Link zu kombinieren. Diese Kombination ist immer dann empfehlenswert, wenn es stärker um die Indexierung geht und weniger um die Auswahl der Canonical URL.
Canonical Tag und Paginierung
Durch die Attribute rel=“next“ und rel=“prev“ kann man mehrere Unterseiten paginieren und so auf eine logische Sequenz hinweisen. Zum Beispiel bei mehreren Seiten einer Shop-Kategorie. Doch Google verarbeitet diese Attribute nicht mehr, wie John Müller bereits 2019 auf Twitter mitteilte. Besser ist es, wenn jede paginierte Seite einer logischer Sequenz per Canonical-Tag auf sich selbst verweist und das Meta Robots Tag index,follow liefert.

Canonical Tag mit Selbstverweis
Viele Content-Management- und Shop-Systeme sind so konfiguriert, dass indexierbare Seiten automatisch ein Canonical Link im HTML-Head setzen, deren URL auf sich selbst verweist. So soll den Suchmaschinen mitgeteilt werden, dass es sich um das Original handelt. Diese Methode ist vollkommen in Ordnung. Allerdings ist es ratsam, die Website zu crawlen und zu bewerten, dass technisch erzeugte Duplikate nicht kanonisch sind, wie Filter-Parameter.
Duplicate Content Checker
Ein Duplicate Content Checker ist hilfreich, um identische Inhalte auf einer Website zu ermitteln. Durch das Scannen vom Quellcode oder von Textinhalten können Duplikate relativ einfach erkannt werden.
Suchmaschinen erkennen doppelte Inhalte und können sie als wertlos deklarieren. Um dies zu vermeiden, sollte man eine kanonische URL angeben und so die Suchmaschine auf die bevorzugte Seite lenken.
- Plagiarism Checker von Grammarly für Texte
- Comparison Tool von Copyscape zum Vergleich von zwei URLs/Texten
Best practices für Canonical Tags
- Es ist wichtig, dass für dieselbe Seite nicht verschiedene kanonische URLs angegeben werden, unabhängig von den angewendeten Kanonisierungsmethoden.
- Bei der Verwendung von hreflang-Elemente muss beachtet werden, eine kanonische Seite in derselben Sprache oder, wenn keine kanonische Seite für dieselbe Sprache vorhanden ist, in der bestmöglichen Ersatzsprache anzugeben.
- Innerhalb einer Website sollten kanonische URL bevorzugt werden. So kann Google die Präferenzen besser erkennen. Auf Duplikate zu verlinken, ist aus SEO-Sicht ungünstig.
- Die Methoden für die Kanonisierung können kombiniert werden, etwa die Verwendung vom rel=“canonical“-Link-Attribut und die Angabe aller kanonischen URLs in einer Sitemap.




